We thank Jack O'Connor (https://github.com/oconnor663) and Project 11 team (https://github.com/PQC-Suite-B) for fruitful discussions and suggestions on improving following writing.
In the following writing, we try to figure out speedup gain in software implementation of NIST standardized post-quantum cryptography (PQC) suite,
by switching to BLAKE3, for faster hashing. We will look at two (recently) NIST standardized PQC schemes - ML-KEM (FIPS 203) and ML-DSA (FIPS 204).
ML-KEM is a next generation key encapsulation mechanism (KEM), designed to resist attackers with access to quantum computer.
Its hardness assumption is based on a lattice problem, which is also deeemed to be hard for quantum computers. ML-KEM allows two peers to agree on a shared-secret, while
communicating over an insecure channel. The agreed upon shared-secret key can then be used with any symmetric-key construction for
faster encrypted and authenticated communication. ML-KEM standard is accessible @ https://doi.org/10.6028/NIST.FIPS.203.
On other hand, ML-DSA is a NIST standardized digital signature algorithm (DSA), designed to replace currently used ECDSA and EdDSA, which are based on the
hardness of discrete logarithm problem (DLP), over elliptic curves. ML-DSA's hardness assumption is also based on a similar kind of lattice problem.
ML-DSA helps in establishing the authenticity and integrity of a message. It also prevents the signer from denying that they signed a message, anytime in future.
ML-DSA standard is accessible @ https://doi.org/10.6028/NIST.FIPS.204.
These two algorithms are very important for future of encrypted communication, specially in a world with Cryptographically Relevant Quantum Computer (CRQC).
By design, both ML-KEM and ML-DSA use NIST standardized hash functions from SHA3 i.e. FIPS 202. SHA3 hash functions offer excellent security
margin. They are based on keccak-p[1600, 24] - 24-rounds keccak permutation, applied on a 1600-bit wide state.
Though they are not as much performant as we would ideally want them to be, in software. Hence, we swap out SHA3-based hashing with BLAKE3, for much faster hashing in NIST PQC schemes.
In following section, we wil observe that a huge chunk of compute time during ML-KEM and ML-DSA execution is spent just on hashing. We hope to reduce
end-to-end latency of NIST PQC algorithms by switching to a faster hash function like BLAKE3. BLAKE3 is known for being the fastest cryptographic hash function.
There are two main reasons for BLAKE3 being that.
- Merklized tree hashing mode, scales BLAKE3's performance, using both SIMD and/or multi-core parallelism, when hashing large input. Large in the sense multiple chunks s.t. each chunk is 1kB.
- BLAKE3 reduces number of rounds to 7, from BLAKE2's 10 and BLAKE's 14, still offering 256-bit of preimage resistance security.
In both ML-KEM and ML-DSA, we use a separate module for SHA3 hashing. Both of the libraries use https://github.com/itzmeanjan/sha3.git as git submodule-based dependency. Note, this SHA3 implementation is a portable C++20 constexpr, header-only library, without any platform specific optimizations. It features compiler-specific pragmas, for auto-vectorization and loop unrolling optimization. It's designed to be simple, readable yet as much performant as possible. This library is also constexpr - meaning, one can evaluate "SHA3_*" hash of a message and compute digest in program compile-time itself. It obviously requires the input message to be known at program compile-time. In following sections, we compare change in performance of NIST PQC schemes by switching to BLAKE3. BLAKE3 team maintains an optimized C implementation @ https://github.com/BLAKE3-team/BLAKE3/tree/1.8.2/c. But again note, BLAKE3 C implementation features platform specific code. For example, on x86_64 target, it can use SSE4.1 or AVX2 or AVX512, based on detected CPU features at runtime. While on aarch64 target, it can use NEON intrinsics for faster SIMD parallel hashing. Hence, it won't be fair to compare change in performance, by using highly optimized BLAKE3 C implementation, as contender, while the baseline is platform-agnostic SHA3 C++ header-only library. For sake of ease in performing following benchmark comparison, while touching the interface of hasher module as little as possible, we stick to portable SHA3 C++ header-only library. But we report a benchmark comparison on the same machine, for SHA3 C++ library vs. XKCP's SHA3 C implementation. XKCP is the official implementation of SHA3 suite, from the Keccak team. It also features a lot of other constructions built on top of keccak permutation. XKCP features many platform specific optimizations, even including handwritten assembly. To make the comparison fair against BLAKE3, we present a performance comparison between our portable C++20 SHA3 library and XKCP. This will show how much off we are from XKCP - the state of the art for keccak permutation based hashing. We use XKCP from https://github.com/XKCP/XKCP.git (commit id: e7a08f7baa3d43d64f5c21e641cb18fe292f2b75). For portable SHA3 C++20 header-only library, we pin to git commit id 5b3641593ec4fbd18d1ce79157f7a0d230580c14. We begin by setting up XKCP. Building it from source.
$ git clone https://github.com/XKCP/XKCP.git
$ git checkout e7a08f7baa3d43d64f5c21e641cb18fe292f2b75
$ git submodule update --init
$ make x86-64/libXKCP.a -j # Optimize for x86_64. Compile-time CPU feature flag detection.
$ ls bin/x86-64/ # List XKCP static library archive and headers
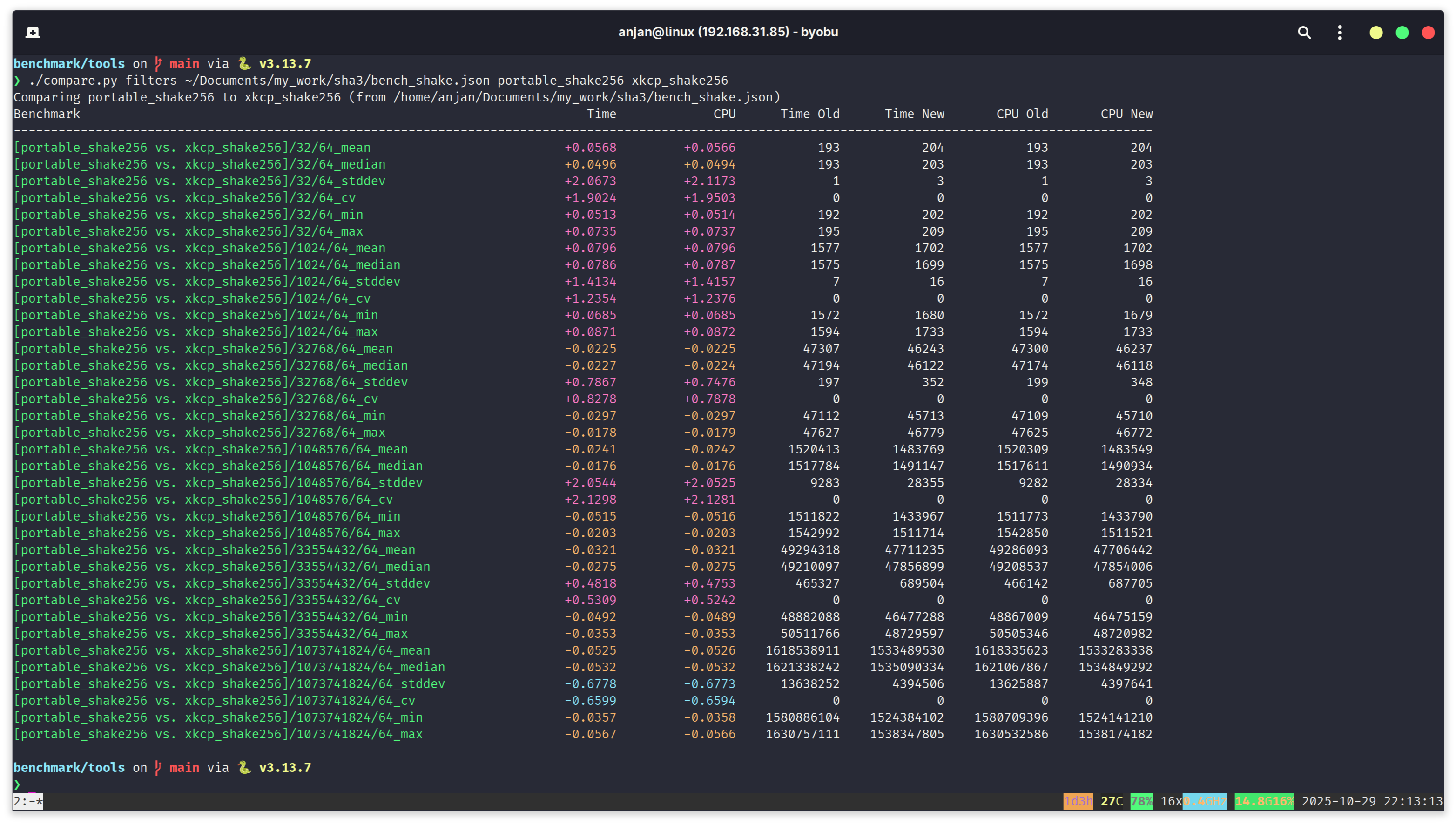
In the following screen capture, we run a performance comparison, on Intel x86_64 Alderlake machine, for portable SHA3 C++ library vs. XKCP C library implementation. We choose to benchmark SHAKE128 eXtendable Output Function (XOF), for variable length input messages such as 32B, 1kB, 32kB, 1MB, 32MB and 1GB. And we sqeeuze 64-bytes out of SHAKE128 instance. For smaller messages, till 1kB, portable C++ SHA3 implementation performs better than XKCP. From about 32kB to 32MB, we see almost no difference in their performance. For the final parameter i.e. 1GB, we see XKCP beating our portable SHA3 C++ implementation, by about a margin of 2%.
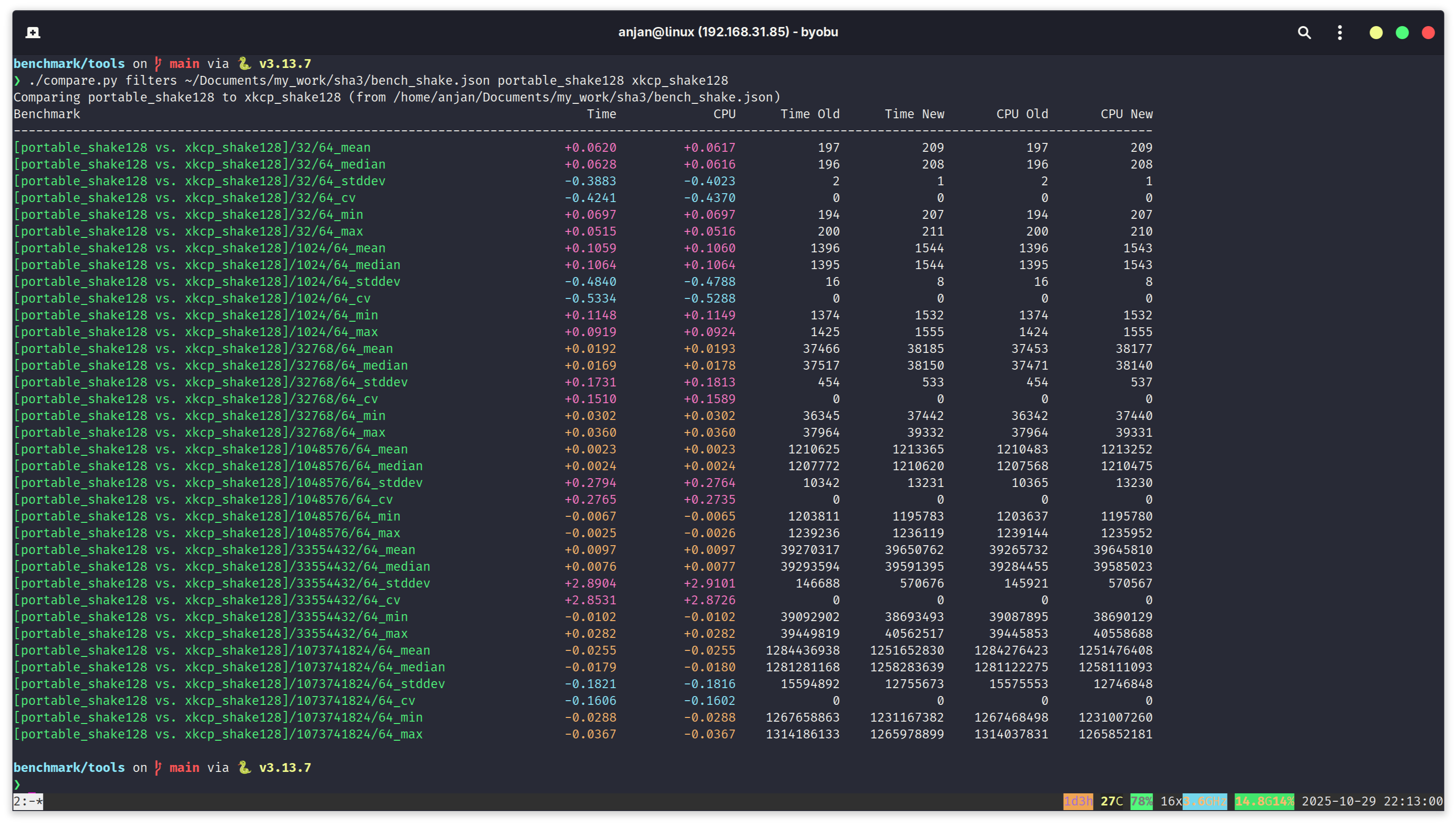
And in the following one, we benchmark SHAKE256 XOF, with variable length input messages and fixed length ouptut digest. We see almost similar performance characteristics. For small messages, till 1kB, XKCP is relatively slower compared to portable implementation. As the message length continues to increase, XKCP starts to beat portable C++ implementation. With these two benchmark comparisons in mind, we begin our exploration of switching to BLAKE3 for faster hashing in NIST PQC schemes.
Let's start with ML-KEM. For sake of this experimentation, we will use C++ header-only library implementation of ML-KEM @ https://github.com/itzmeanjan/ml-kem.git (commit id: 0d7996dad0e8ef343fb957eb58e58d861cffc938). For understanding if it's worth replacing SHA3-based hashing with much faster BLAKE3-based hashing, we will use Linux performance analysis tool perf, when benchmarking ML-KEM. Following screen capture demonstrates, during ML-KEM encapsulation and decapsulation, 33.19% time is spent in generate_matrix() function. generate_matrix() simply generates a matrix, using the method of rejection sampling, given a seeded eXtendable Output Function (XOF) such as SHAKE128. Another big compute time consumer is generate_vector() function, costing us 5.91% of time. generate_vector() also samples a vector of polynomials, from a seeded SHAKE256 XOF instance. These two functions, mainly absorbs bytes into keccak[1600] permutation state; permutes using 24-rounds keccak permutation and squeezes arbitrary many bytes out of the keccak[1600] instance. This costs us 39.1% of time during ML-KEM encapsulation and decapsulation - spent just on hashing. We can try to optimize ML-KEM, by using faster hash function like BLAKE3.

We prepare BLAKE3 C implementation to be used with ML-KEM and ML-DSA. As both ML-KEM and ML-DSA libraries are implemented as C++ header-only libraries, we can simply wrap BLAKE3 C API as sponge like functions in a C++ class. Like shown below. We will replace any use of SHA3 hash functions and xofs, with following interface.
#pragma once
#include "blake3.h"
#include <cstring>
#include <span>
namespace ml_kem_hashing {
// BLAKE3 hashing wrapper, behaving like an eXtendable Output Function (XOF).
//
// C++ class wrapper on top of API definition
// @ https://github.com/BLAKE3-team/BLAKE3/blob/e0b1d91410fd0a344beda6ee0e6f1972ad04be08/c/README.md#api
struct blake3_hasher_t
{
private:
blake3_hasher internal_hasher;
bool finalized;
size_t squeeze_from;
public:
// Initialize BLAKE3 hasher context.
blake3_hasher_t()
{
blake3_hasher_init(&this->internal_hasher);
this->finalized = false;
this->squeeze_from = 0;
};
// Absorb arbitrary length message into BLAKE3 hasher context.
// Invoke it as many times needed before hasher is finalized.
void absorb(std::span msg)
{
if (!this->finalized) {
blake3_hasher_update(&this->internal_hasher, msg.data(), msg.size());
}
}
// After absorbing full message, finalize hasher, so that it can be used for squeezing output.
// Once finalized, hasher instance can't be used for further absorption.
void finalize()
{
if (!this->finalized) {
blake3_hasher_finalize(&this->internal_hasher, nullptr, 0);
this->finalized = true;
}
}
// After finalizing hasher, start squeezing arbitrary sized output, as many times needed.
void squeeze(std::span dig)
{
if (this->finalized) {
blake3_hasher_finalize_seek(&this->internal_hasher, this->squeeze_from, dig.data(), dig.size());
this->squeeze_from += dig.size();
}
}
// Resets hasher to post-init state. After reseting, the hasher is ready for
// another round of absorb -> finalize -> squeeze cycle.
void reset()
{
blake3_hasher_reset(&this->internal_hasher);
this->finalized = false;
this->squeeze_from = 0;
}
};
}
NIST standard for ML-KEM i.e. FIPS 203 proposes parameters for three security levels. For this demonstration, we will only focus on ML-KEM-768, offering 192-bit of security. Let's run the benchmarks on an Intel x86_64 desktop machine, running Linux 6.17.0-5-generic kernel. The benchmark executable is compiled using GCC 15.2.0, with flags -O3 -march=native.
$ git clone https://github.com/itzmeanjan/ml-kem.git
$ pushd ml-kem
$ git checkout 0d7996dad0e8ef343fb957eb58e58d861cffc938 # HEAD of `master` branch, at the time of writing
$ make benchmark # Or run `make perf` if you have google-benchmark with libPFM
$ popd
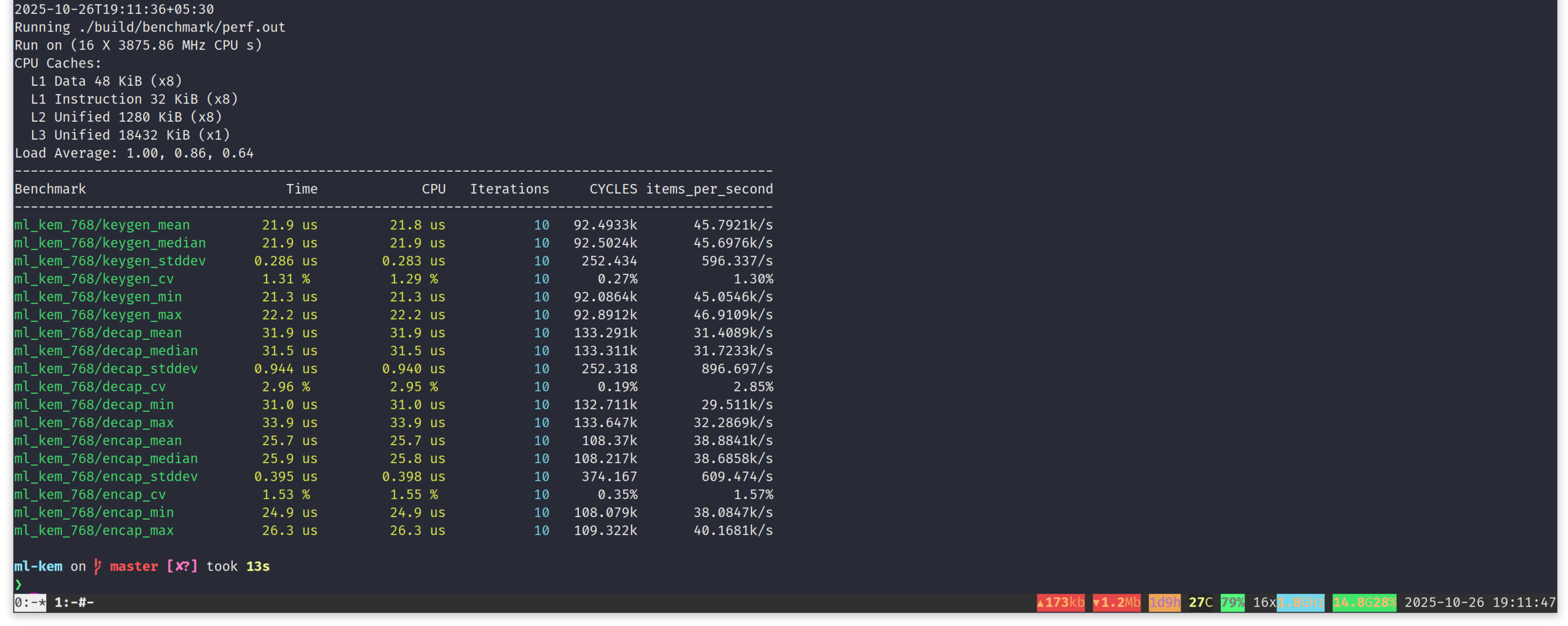
Important numbers to note down. For ML-KEM-768, on Intel x86_64 Alderlake architecture, keygen, encaps and decaps take following median time to execute.
| ML-KEM Algorithm | Median Time to Execute |
|---|---|
| Key Generation | 21.9 us |
| Encapsulation | 25.9 us |
| Decapsulation | 31.5 us |
Now we can swap out hashing with SHA3 and switch to BLAKE3 hasher API, we just defined above. We will call these instances of ML-KEM as ML-KEM-B. The necessary patch for ML-KEM-B lives @ https://github.com/itzmeanjan/ml-kem/tree/ml-kem-b (commit id: 03ca3cd1febfd16486324a882f44c93b3dbcab51). Benchmarking on same the machine, gives us following result.
$ git clone https://github.com/itzmeanjan/ml-kem.git
$ pushd ml-kem
$ git checkout ml-kem-b # HEAD of `ml-kem-b` branch, commit id: 03ca3cd1febfd16486324a882f44c93b3dbcab51
$ make benchmark # Or run `make perf` if you have google-benchmark with libPFM
$ popd
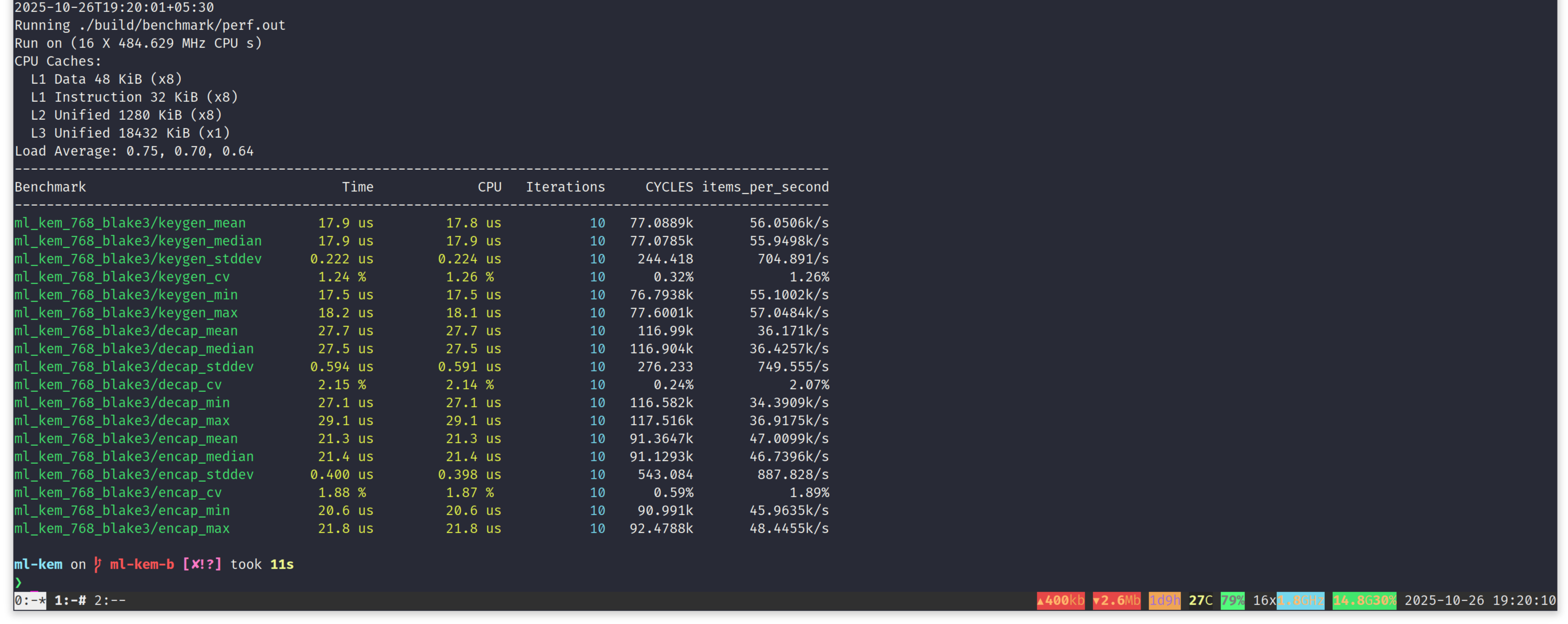
Let's note down median time to execute ML-KEM-768-with-BLAKE3 keygen, encaps and decaps.
| ML-KEM-B Algorithm | Median Time to Execute |
|---|---|
| Key Generation | 17.9 us |
| Encapsulation | 21.4 us |
| Decapsulation | 27.5 us |
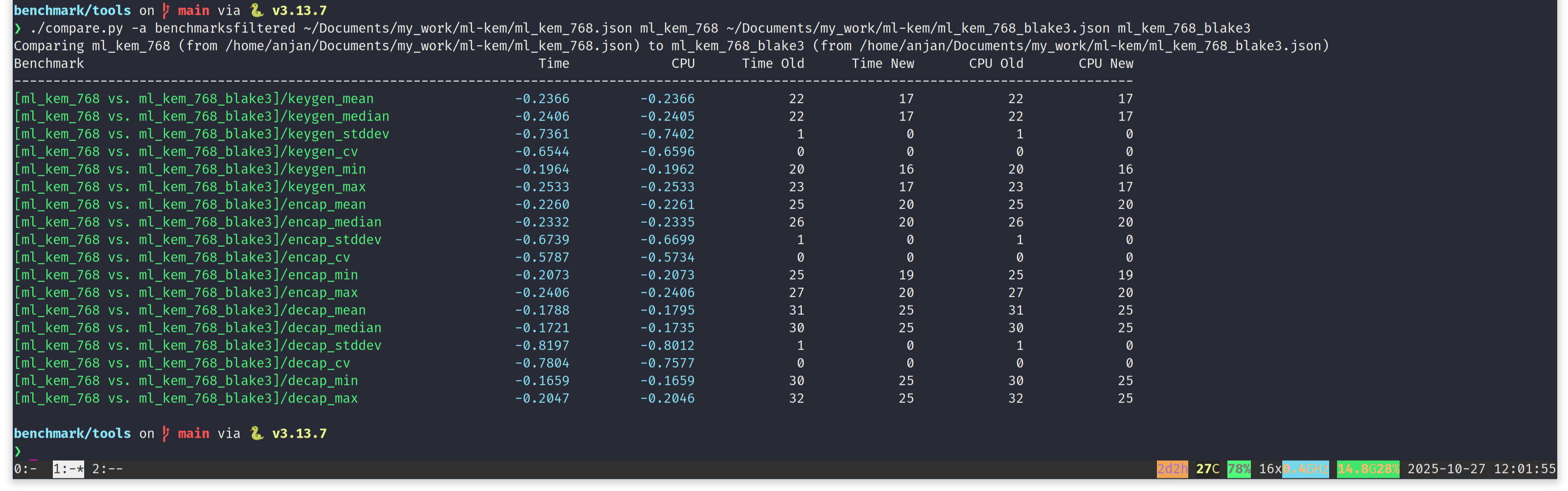
Comparing ML-KEM performance metrics table with ML-KEM-B table, shows a clear advantage in choosing BLAKE3 for hashing purposes, in ML-KEM.
On a side note, we are using google-benchmark for benchmarking ML-KEM functions. And google-benchmark comes with a nice tool for comparing
benchmark results. We can use that to produce a nice tabular report, showing performance improvement or degradation by choosing to use BLAKE3 for hashing in ML-KEM algorithms.
How to use google-benchmark comparison tool is described in a guide @ https://github.com/google/benchmark/blob/v1.9.4/docs/tools.md.
Using the benchmark comparison tool for comparing performance of ML-KEM vs. ML-KEM-B, on x86_64, gives us following result.
In short, by switching to BLAKE3, ML-KEM-768 reduces latency in all three algorithms.
- Key generation is taking 24.06% less time.
- Encapsulation is taking 23.32% less time.
- Decapsulation is taking 17.21% less time.
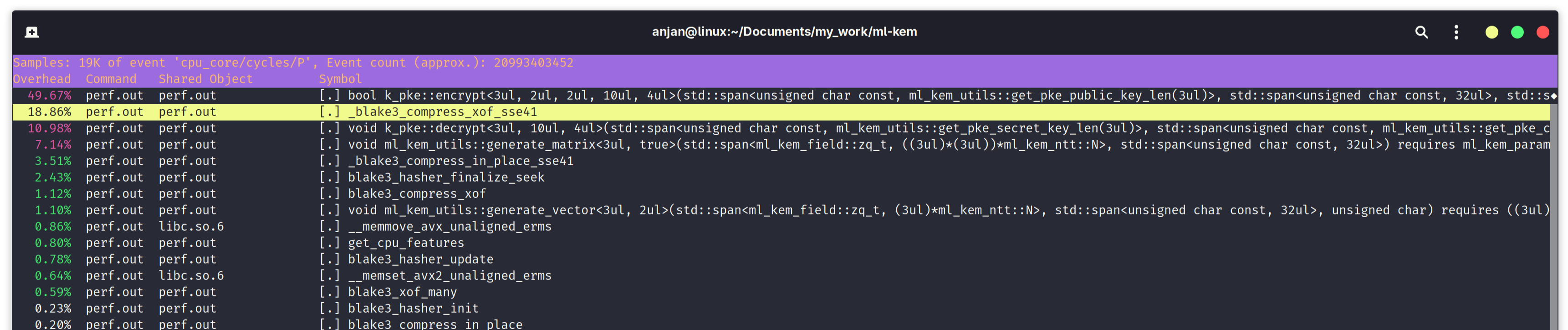
Now if we use Linux kernel's perf tool to inspect performance bottleneck in the ML-KEM-B variant, we notice that only 7.14% time is spent in generate_matrix(), much lesser than ML-KEM variant. Instead now blake3_compress_xof_sse41() is taking 18.86% of encapsulation and decapsulation compute time. It clearly show BLAKE3 C implementation intelligently finds optimized code path and executes it based on available CPU features. That's exactly what get_cpu_features() is for, in following perf report. Our SHA3 C++ header-only library implementation lacks this feature. Also note that, SHA3 hash functions are not tree hashing mode - there are less SIMD parallelism opportunities to exploit for faster hashing in SHA3. Ignoring that fact, BLAKE3 has reduced latency in ML-KEM function's running time. A clear win.
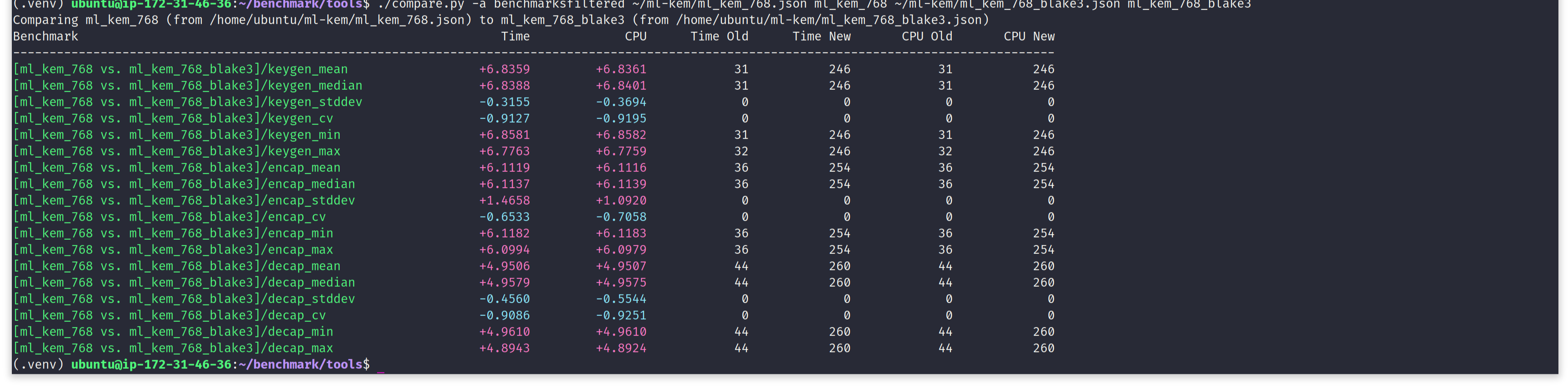
For sake of completeness, we run ML-KEM vs. ML-KEM-BLAKE3 benchmark comparison on an aarch64 server-grade CPU i.e. AWS c8g.large instance, featuring a Graviton4 CPU. More resources on AWS c8g.large instance @ https://aws.amazon.com/ec2/instance-types/c8g. To our complete surprise, ML-KEM-BLAKE3 turns out to be multiple times slower compared to the base version i.e. NIST ML-KEM. We suspect it is because of some sort of compile-time misconfiguration or issues with runtime CPU feature detection, in BLAKE3 C implementation.
In the rest of the post, we will focus on ML-DSA and see how does its performance characteristics change by switching to BLAKE3. NIST standard for ML-DSA i.e. FIPS 204 recommends using hash functions and extendable output functions from SHA3 standard i.e. FIPS 202. In this experiment, we use ML-DSA C++ header-only library implementation @ https://github.com/itzmeanjan/ml-dsa.git (commit id: dfb9b0fa187fa73d5d239f92b9625f3d7738da4c). ML-DSA standard proposes parameters for three security levels. In following experiment, we choose to work with only ML-DSA-65 i.e. the parameter set providing us with 192-bit security. To begin with, we will use Linux kernel's perf tool to find performance bottleneck in ML-DSA-65 keygen, sign and verify, separately.
In the following screen capture of $ perf report command output of ML-DSA-65 key generation algorithm, we see 49.67% time is spent on expand_a(). What expand_a() does is, it takes a seed to initialize a SHAKE128 XOF instance, from which it deterministically samples a public matrix A, using the method of rejection sampling. Below that, two invocations of expand_s(), consuming upto 7.15% and 6.37% of time spent during key generation. expand_s() similarly samples LWE secret vector s, from a seeded SHAKE256 XOF instance. These three function calls combined, takes up a whopping 63.19% of total execution time of ML-DSA key generation algorithm. And it's all basically hashing using XOFs, defined in SHA3 standard.

In following screen capture, we find main bottlenecks in ML-DSA-65 signing execution. Like in key generation, we have to invoke expand_a() to deterministically sample public matrix A, from a seeded SHAKE128 XOF instance. It takes up 7.55% of total execution time. Both expand_mask() and sample_in_ball() sample from a seeded SHAKE256 XOF instance. expand_mask() costs 7.52% of execution time of sign algorithm. During ML-DSA signing, we end up spending 15.7% of total time in just hashing using SHA3.

And finally, in the following screen capture, we find performance bottleneck in ML-DSA signature verification flow. We again encounter expand_a(), taking up a whopping 46.98% of execution time of verify algorithm. It absorbs a fixed length seed into the keccak[1600] permutation state; permutes the state using 24-rounds keccak permutation and finally squeezes bytes out of the keccak[1600] permutation state, for rejection sampling coefficients of public matrix A. That's a huge chunk of verification algorithm's compute time, being occupied in just hashing. It's quite evident that switching to a faster hash function should improve performance.

Let's run the benchmarks on an Intel x86_64 Alderlake mobile CPU, running Linux 6.17.0-5-generic kernel. Benchmark executable is compiled with GCC 15.2.0, with flags -O3 -march=native.
$ git clone https://github.com/itzmeanjan/ml-dsa.git
$ pushd ml-dsa
$ git checkout dfb9b0fa187fa73d5d239f92b9625f3d7738da4c # HEAD of `master` branch, at the time of writing
$ make benchmark # Or run `make perf` if you have google-benchmark with libPFM
$ popd
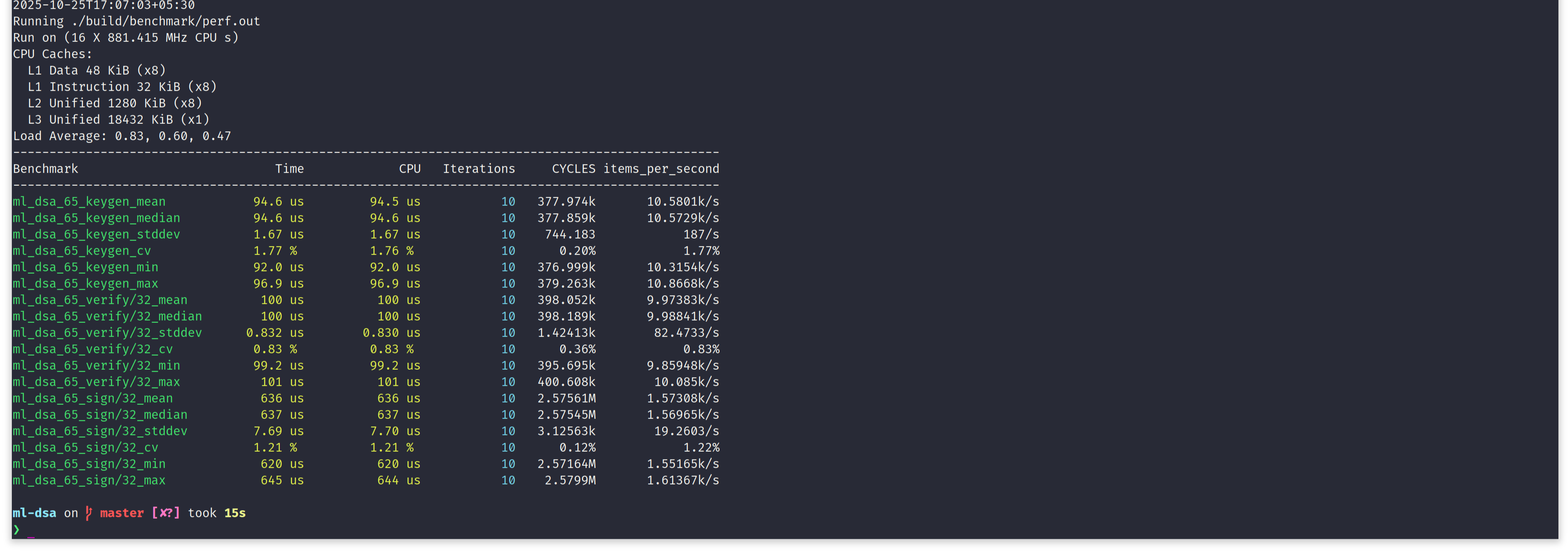
Important numbers to note down, from above screen capture - median time to execute ML-DSA-65 key generation, signing and verification. Note, when benchmarking signing and verification, we work with fixed size 32-bytes message.
| ML-DSA Algorithm | Median Time to Execute |
|---|---|
| Key Generation | 94.6 us |
| Signing | 637 us |
| Verification | 100 us |
It's time to replace hashing with SHA3, by BLAKE3 hasher. We will call these instances of ML-DSA as ML-DSA-B i.e. ML-DSA with BLAKE3. The necessary patch for ML-DSA-B lives @ https://github.com/itzmeanjan/ml-dsa/tree/ml-dsa-b (commit id: 29204af36d7d873efeaa41db4980a4126097621c). Benchmarking on the same machine, gives us following result. For reproducing benchmark results of ML-DSA-B, run following commands.
$ git clone https://github.com/itzmeanjan/ml-dsa.git
$ pushd ml-dsa
$ git checkout ml-dsa-b # Branch holding ML-KEM-B implementation, commit id: 29204af36d7d873efeaa41db4980a4126097621c
$ make benchmark # Or run `make perf` if you have google-benchmark with libPFM
$ popd
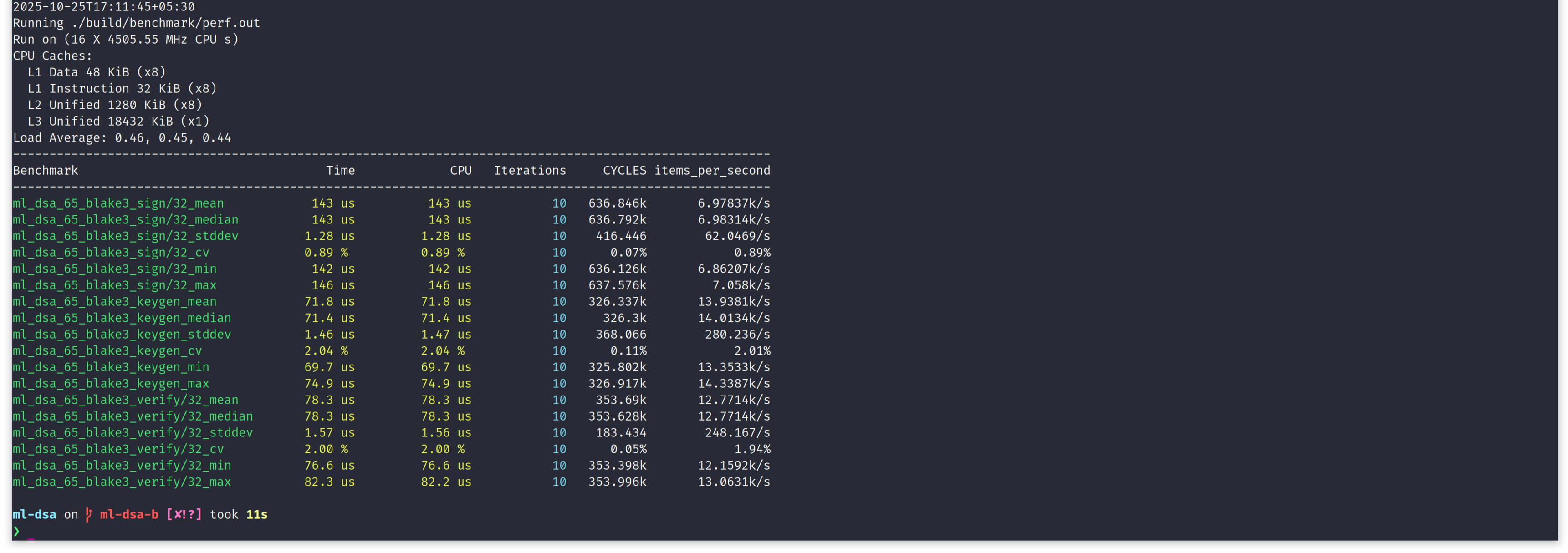
Let's note down median time to execute key generation, signing and verification, for ML-DSA-65 with BLAKE3 for hashing.
| ML-DSA-B Algorithm | Median Time to Execute |
|---|---|
| Key Generation | 71.4 us |
| Signing | 143 us |
| Verification | 78.3 us |
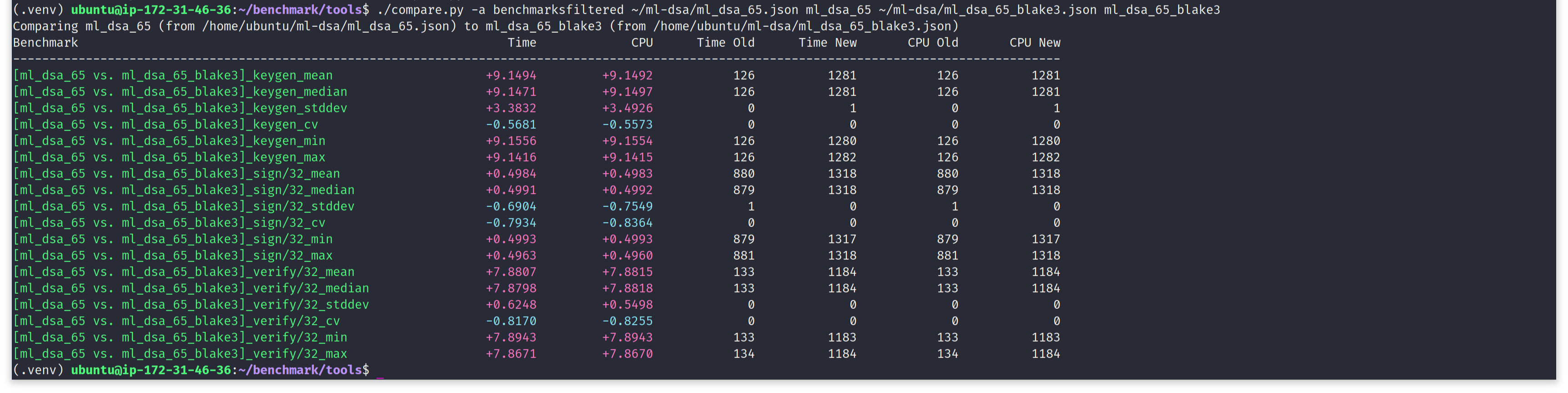
Comparing above two tables, clearly shows switching to BLAKE3, is advantageous, in case of ML-DSA too. For all three algorithms, ML-DSA-B shows a strong upperhand over NIST ML-DSA, from software performance point of view. Let's use google-benchmark's comparison tool to get a nice tabular output of performance comparison between ML-DSA-65 and ML-DSA-65-BLAKE3. In following screen capture, we see, by choosing to use BLAKE3 for hashing in ML-DSA-65, we are saving a substantial amount of execution time.
- Key generation is taking 24.55% lesser time.
- Message signing is taking 77.52% lesser time.
- Signature verification is taking 21.79% lesser time.
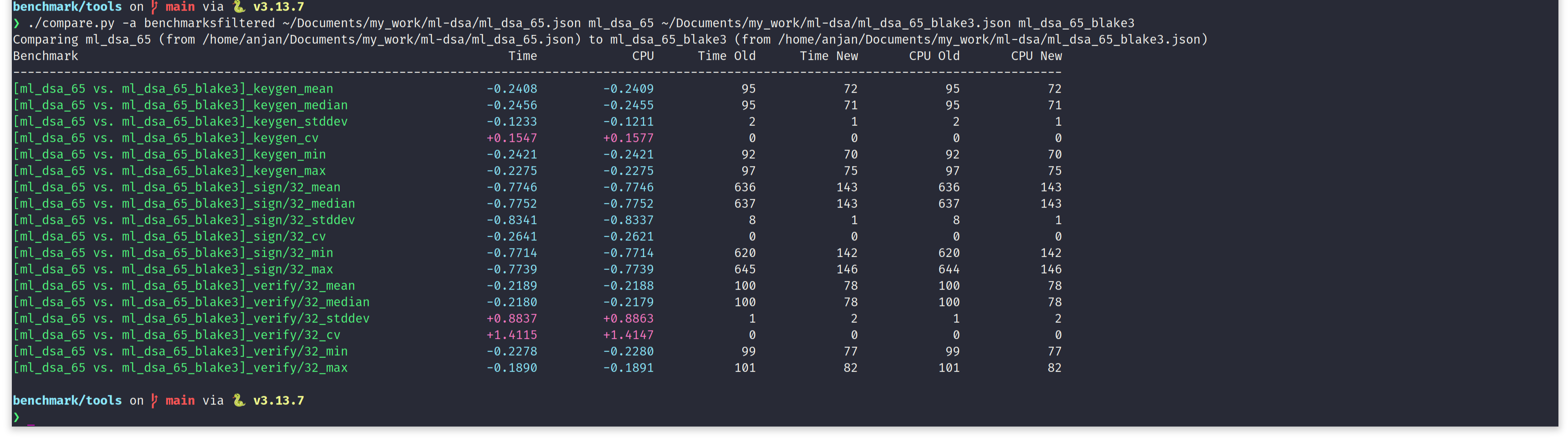
The performance improvement in message signing looks too good to be true. It's not consistent with keygen and verify. And we have an explanation for it. ML-DSA is a digital signature scheme of "Fiat-Shamir with Aborts" paradigm - simply put, when signing a message, it may need to abort and restart again, multiple times, based on what message is being signed or what random seed is being used for the default "hedged" signing mode. To reduce the influence of sampling from a cryptographically secure pseudo-random number generator (CSPRNG), we fix the seed. A CSPRNG, initialized with a fixed seed, is used for sampling ML-DSA inputs i.e. message, context and seed, when benchmarking ML-DSA and ML-DSA-B sign algorithm. But note, due to the use of different hash functions in ML-DSA and ML-DSA-B, we end up deriving different matrices and vectors, from SHA3 and BLAKE3 hasher, respectively. Both BLAKE3 and SHA3 hasher gets initialized with the same input and they produce different output - as expected. During the execution of sign_internal(), ML-DSA-B receives different pseudo-randomness, than baseline ML-DSA. As a result of it, signing procedure takes different number of attempts (read aborts-then-restarts) to succeed for ML-DSA vs. ML-DSA-B, even when all the inputs are same. That's exactly why we encounter this too good to be true performance boost. We roughly estimate, if ML-DSA didn't require abort in middle of signing, performance gain by switching to BLAKE3 would be more consistent with others - in the range of 20-30%, on x86_64. That will be on par with ML-DSA keygen and verify. Even ML-KEM shows similar kind of performance boost by switching to BLAKE3.
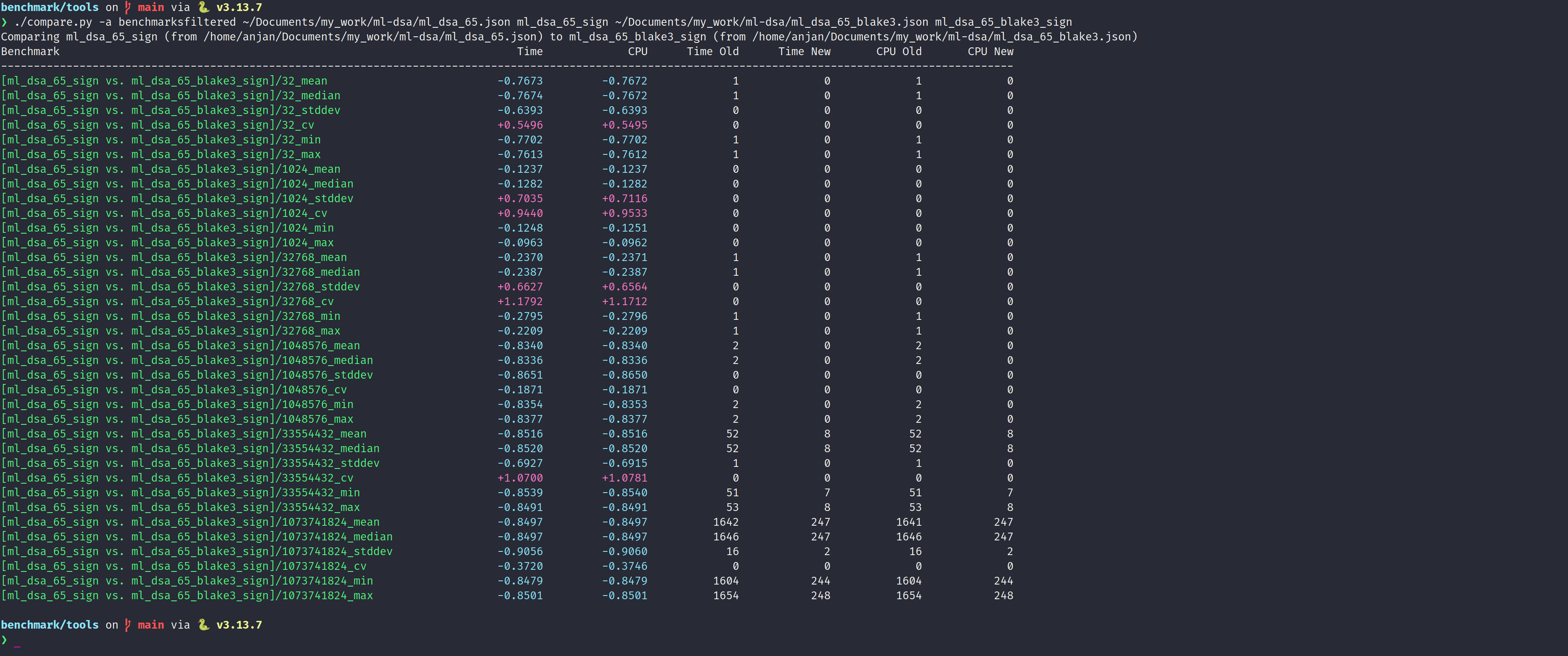
To get a better idea of BLAKE3's contribution, in ML-DSA message signing and signature verification performance, we experiment with variable sized messages. We choose to benchmark with random messages of following six sizes: 32B, 1kB, 32kB, 1MB, 32MB and 1GB. Notice, each input size is separated from its neighbour by a distance of 32x. We benchmark compare them inside the same environment. To limit the effect of intermittent abort during signing a message with ML-DSA, we fix the seed for CSPRNG, from where all the inputs are sampled. Hence we benchmark sign(), with exactly the same mesasge and context for both ML-DSA and ML-DSA-B. This is the best we could come up with to limit noise.

When signing a 32B message, ML-DSA-B turns out to be 76.74% faster than baseline ML-DSA. When we sign a 1kB message, the performance gain by switching to ML-DSA-B doesn't get pronounced that well - only 12.82% faster than baseline. And signing a 32kB message, with ML-DSA-B is 23.87% faster than baseline. We can already see the inconsistency in performance gain. As we move towards even longer messages, such as 1MB, we see BLAKE3's upperhand in hashing longer messages, starts to kick in. We see a whopping ~83% improvement in latency when signing 1MB, 32MB and 1GB message. As we sign longer messages, those messages first need to get compressed into a shorter 64-bytes value mu (μ), using BLAKE3 or SHA3. In line 330 of above screen capture, BLAKE3 really shines compared to SHA3. Thanks to SIMD parallel tree hashing mode. For long messages, line 330 is the actual bottleneck. ML-DSA sign algorithm itself is not anymore stopping us from signing faster.
It's fairly hard to exactly pinpoint how fast we can sign a message with ML-DSA-B, compared to baseline ML-DSA, because of ML-DSA being a digital signature scheme of "Fiat-Shamir With Aborts" paradigm.
In following benchmark comparison, we see the result being inconsistent for various message sizes. The performance improvement when signing a message with ML-DSA-B,
ranges from (12-85)%, for the input message size ranging from 32B to 1GB. But we conclude, with certainty, that when signing really long messages (say >=1MB), we will always benefit from SIMD parallel BLAKE3 hashing.
SHA3 won't beat it. As the bottleneck moves from signing to preparing material for signing i.e. hashing message, to compute mu.
BLAKE3 compresses chunks of 1kB, in parallel. Each chunk of 1kB is compressed into a short chaining-value (CV), which is a leaf of a Merkle Tree.
If we have many chunks which are ready to be absorbed into BLAKE3 permutation state, then we benefit the most from SIMD parallelism, by compressing 4x, 8x or even 16x
of these chunks, in parallel. Each hasher.absorb() call in above screen capture, makes a call to the underlying C implementation's blake3_hasher_update().
In line 330 of above screen capture, BLAKE3 will have most number of 1kB chunks ready to be compressed, when message to be signed is long.
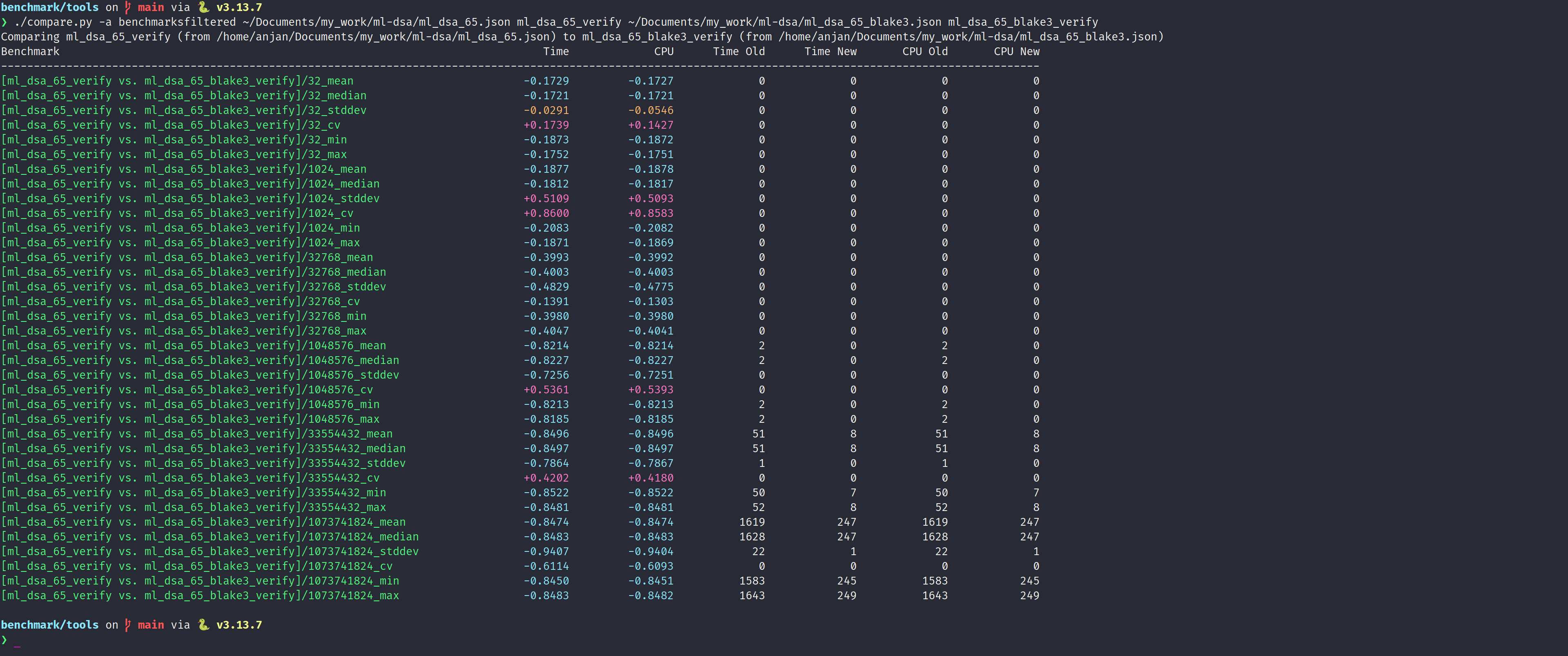
When verifying a signature, ML-DSA-B is moderately faster than baseline ML-DSA for short and mid-sized messages. For messages, in range of 32B to 1kB, ML-DSA-B has 18% lower latency than baseline. This result is consistent with gain in keygen. As number of BLAKE3 chunks increase i.e. we verify signature over message of 32kB, we see performance boost of upto 40%. As we continue increasing message size, even further to 1MB, then 32MB and finally 1GB, the comparative cost of signature verification drops significantly, even upto 85%. Majority of the compute time is spent in hashing the message to compute mu, which gets signed, by ML-DSA.sign_internal(). For very long messages, signature verification itself is not anymore a bottleneck. Rather we spent a lot of time preparing material which was signed i.e. mu. This behaviour is same as what we just observed with signing.
After applying ML-DSA-B patch, we analyse changes in performance bottleneck for ML-DSA-65-BLAKE3 keygen, sign and verify. Let's begin with ML-DSA-65-BLAKE3 key generation. In following screen capture, we see BLAKE3 function blake3_compress_xof_sse41() taking up 33.06% of execution time during key generation. Several small chunks of execution time is also occupied by other BLAKE3 functions such as compression or finalization. The call to get_cpu_features() shows BLAKE3 C implementation is inspecting supported hardware features at runtime and executing best code path for faster SIMD parallel hashing. The expand_a() function, which was occupying 49.67% time, when hashing with SHA3, is nowhere to be seen.

In following screen capture, we look for bottleneck in execution of signing algorithm with ML-DSA-B. The bottleneck has shifted from expand_a() or expand_mask() to our familiar blake3_compress_xof_sse41(). We are still spending a minimum of 16.68% time in compressing BLAKE3 chunks (read hashing), but overall it's taking us lesser time, due to faster running time of BLAKE3, in software.

Finally we look at the current state of performance bottleneck in signature verification algorithm, with ML-DSA-B. And again, as expected, expand_a(), which was occupying 49.67% of execution time, with standard ML-DSA-65, is nowhere to be seen as a bottleneck. Instead we find that, we are spending 28.1% of execution time in compressing BLAKE3 chunks, invoking blake3_compress_xof_sse41(), exploiting SSE4.1-based SIMD parallelism.

For sake of completeness in our analysis, we run performance comparison of ML-DSA vs. ML-DSA-B, on an aarch64 server-grade CPU i.e. AWS c8g.large instance, featuring a Graviton4 CPU. Same as ML-KEM, ML-DSA-B turns out to be several times slower than ML-DSA, on aarch64 target. Our suspicion is, it is due to some sort of compile-time misconfiguration or issues with runtime CPU feature detection, in BLAKE3 C implementation, when targeting aarch64.
With this, we finish our analysis on "Is there any advantage of switching to BLAKE3 for faster hashing in NIST PQC standards?".
We answer affirmatively. We analyzed 192-bit security parameter for both ML-KEM and ML-DSA. For sake of experimentation, we chose to use C++ header-only library implementation
of ML-KEM https://github.com/itzmeanjan/ml-kem.git and ML-DSA https://github.com/itzmeanjan/ml-dsa.git, as baseline.
Both of them use SHA3 C++ header-only implementation @ https://github.com/itzmeanjan/sha3.git, as git submodule based dependency.
We replace hashing with SHA3 by BLAKE3 C implementation @ https://github.com/BLAKE3-team/BLAKE3/tree/1.8.2/c.
By switching to BLAKE3, we observe quite substantial performance gain for both ML-KEM and ML-DSA, on x86_64 target.
ML-KEM-B keygen() is 24.06% faster, encaps() is 23.32% faster and decaps() is 17.21% faster, compared to standard ML-KEM.
ML-DSA-B keygen() is 24.55% faster, sign() is 77.52% faster and verify() is 21.79% faster, compared to standard ML-DSA.
Last but not least. In this writing, we have established that switching to BLAKE3 for faster hashing can be overall good for NIST PQC standard ML-KEM and ML-DSA.
But we must mention, that is not the only way to speed up ML-KEM and ML-DSA. Recall that, we mentioned SHA3 hash functions and extendable output functions provide
us with an excellent security margin - as they are backed by keccak-p[1600, 24] i.e. 24-rounds keccak permutation on 1600-bit wide state. But this is quite a conservative
parameterization. We can halve the number of rounds to 12 and we get TurboSHAKE, which was formally specified in https://eprint.iacr.org/2023/342.
A Rust library implementation of TurboSHAKE @ https://github.com/itzmeanjan/turboshake/tree/v0.5.0,
shows interesting performance characteristics. It almost doubles the throughput of hashing, powered by the same keccak permutation. A future work will be to experiment with using TurboSHAKE instances for faster
hashing in NIST PQC suite. That will allow us to compare performance gain, in NIST PQC suite, by switching to BLAKE3 vs. TurboSHAKE.