Last week I was working on implementing parallel cholesky factorization on accelerators, using SYCL DPC++, though obtained
performance was not impressive due to some points I recognized and noted here.
Today I plan to expand on those points, while splitting factorization into computationally ordered and dependent steps, which eventually proves to
attain better speed up than previous implementation of mine.
I abstractly start working with one symmetric positive definite square matrix AN x N, which I convert into UN x N. Obtaining the other
half is as easy as performing a transpose of UN x N, giving me LN x N.
Once both of these halves are computed, 👇 can be checked, while keeping it in mind that as these computations are performed on accelerated
environments, some floating point errors are inevitable.

I begin with an easy step, where I first initialise UN x N with AN x N and then parallelly zero out lower triangular portion ( read cells below pivots ) of UN x N. During the further course
of computation I'll never need to access those memory locations. As lower triangular portion of matrix is not rectangular shaped, I have to
spawn N x N parallel work-items to zero out cells below pivots, though a substantial number of work-items will do nothing useful,
which I ensure using conditional statement --- sadly resulting into divergent control flow.
I write the respective kernel as 👇
// see https://github.com/itzmeanjan/matrix_factorization/blob/master/cholesky_factorization.cpp#L15
19| h.parallel_for(
20| nd_range<2>{range<2>{dim, dim}, range<2>{1, wg_size}},
[=](nd_item<2> it) {
const uint i = it.get_global_id(0);
const uint j = it.get_global_id(1);
if (i > j) {
a_mat_out[i][j] = 0.f;
27| }
28| });
Next I've to run through a set of steps for N-many rounds, as matrix dimension is N x N. During each round, I go through following 2 steps of computations, in-order, as they have computational dependency.
- Pivot Calculation
- Pivot Row Calculation
Actually during each of these N-rounds, a pivot is selected and all operations are performed around it. These operations only compute/ access cells above (or including)
pivots i.e. upper triangular portion of matrix.
In first step of round-k, say pivot Uk, k is selected, all I do is atomically compute updated pivot value by subtracting squared values at cells Ui, k
where 0 <= i < k. Primarily I spawned N x N work-items for this step and was using conditional statements
so that only work-items representing cells above selected pivot are able to atomically update pivot, by subtracting squared value of self. But this
results into divergent control flow, costing high, as most of work-items do nothing useful after work-groups are fetched for computation. But one thing I noticed,
during this step only cells above/ including selected pivot are accessed, which opens up opportunity for only spawning k
work-items, parallelly (and atomically) computing updated value of selected pivot Uk, k.
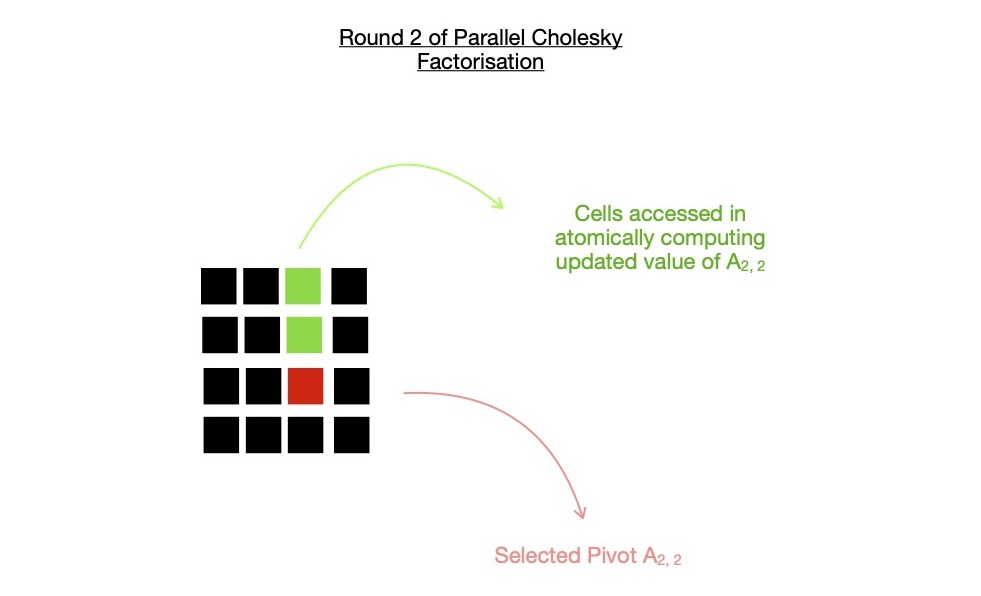
In following diagram, I depict this step of round-k (= 2), by only spawning k(= 2) work-items, atomically computing selected pivot U2, 2,
by subtracting Ui, 22, where i = {0, 1}.
Before step one is completed, I've to spawn another kernel, for computing a single cell of UN x N, by performing square root of selected pivot Uk, k. It's easy and cheap to spawn a kernel, which accesses single pivot cell and computes updated value, rather than implicitly transferring matrix data to host; computing same and finally again implicitly transferring data back to device. Data movement is expensive, costs lots of computation cycles and I aim to minimize so, which is why for improving performance I decide to spawn a single task kernel, which just updates selected pivot on device, while fully avoiding data movement --- low cost !
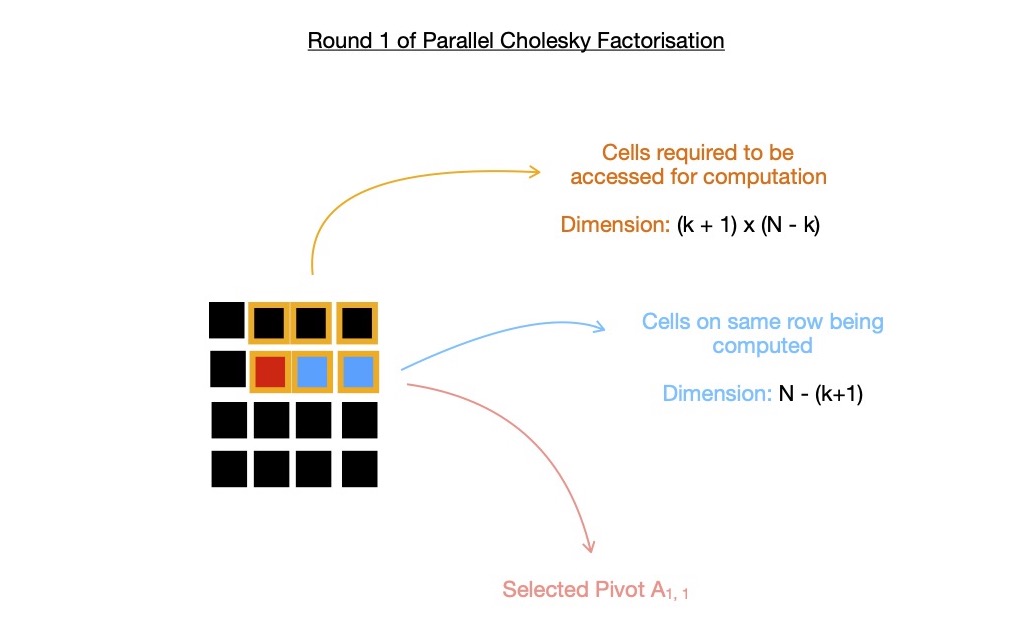
In second step, I compute updated values of cells, living on selected pivot row ( i.e. Ak, _ ), to be more specific
only those rightwards from pivot cell Ak, k. During this step, I need to access cells from a submatrix of dimension
(k + 1) x (N - k). Following same logic as mentioned before, I decide to only spawn N - (k + 1)
work-items, which removes need for using conditional statements, required when spawning N x N work-items, resulting into
most work-items sitting idle. Notice, for any selected k ( >= 0 && < N ), only N - (k + 1) columns have column index
higher than selected pivot on same row --- so this time no divergence in control flow, all work-items do something useful.
In following depiction, I use k = 1 i.e. in round-1 of cholesky factorization, I compute N - (k + 1) = 2 cells on pivot row i.e. U1, i where i = {2, 3}, while
accessing cells from marked submatrix. You may want to take a look at what exactly is computed by each of N - (k+1) work-items
here.
After completion of both steps, in each round, all cells of pivot row Uk, _ hold final value i.e. what it's supposed to be in upper triangular portion after factorization.
And after N-many rounds, upper triangular portion is stored in UN x N.
I decide to run benchmarks on updated cholesky factorization implementation.
Previous implementation on same hardware performed worse for N = 1024, completing in ~400ms, which is now improved to ~370ms. You may also notice, as matrix dimension
keeps increasing, floating point math error also keeps increasing, which is found when comparing LN x N x UN x N with AN x N. As I compile
DPCPP program with -ffast-math option, allowing fast, aggressive, lossy floating point computation, I expect deviation of this scale.
running on Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
Cholesky Factorization:
dimension time max deviation
32 x 32 5 ms 7.62939e-06
64 x 64 5 ms 3.05176e-05
128 x 128 10 ms 0.00012207
256 x 256 20 ms 0.000305176
512 x 512 67 ms 0.0012207
1024 x 1024 370 ms 0.00610352
Finally I run improved implementation on another CPU, getting to much better performance of ~172ms of completion time, for N = 1024. Previous unoptimised version on same hardware with same launch configurations resulted into completion time of ~221ms --- ~22% performance boost !
running on Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz
Cholesky Factorization:
dimension time max deviation
32 x 32 8 ms 1.14441e-05
64 x 64 6 ms 3.8147e-05
128 x 128 10 ms 9.15527e-05
256 x 256 21 ms 0.000305176
512 x 512 52 ms 0.000976562
1024 x 1024 172 ms 0.00524902
I keep optimised implementation of cholesky factorization here for future reference.
In coming days, I'll take up other problems for solving them on accelerated environments, as I generally do.
Have a great time !